约 1428 个字 7 张图片 预计阅读时间 7 分钟 共被读过 次
ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding¶
文章信息
Abstract¶
Abstract
Recent advancements in multimodal pre-training have shown promising efficacy in 3D representation learning by aligning multimodal features across 3D shapes, their 2D counterparts, and language descriptions. However, the methods used by existing frameworks to curate such multimodal data, in particular language descriptions for 3D shapes, are not scalable, and the collected language descriptions are not diverse. To address this, we introduce ULIP-2, a simple yet effective tri-modal pre-training framework that leverages large multimodal models to automatically generate holistic language descriptions for 3D shapes. It only needs 3D data as input, eliminating the need for any manual 3D annotations, and is therefore scalable to large datasets. ULIP-2 is also equipped with scaled-up backbones for better multimodal representation learning. We conduct experiments on two large-scale 3D datasets, Objaverse and ShapeNet, and augment them with tri-modal datasets of 3D point clouds, images, and language for training ULIP-2. Experiments show that ULIP-2 demonstrates substantial benefits in three downstream tasks: zero-shot 3D classification, standard 3D classification with fine-tuning, and 3D captioning (3D-tolanguage generation). It achieves a new SOTA of 50.6% (top1) on Objaverse-LVIS and 84.7% (top-1) on ModelNet40 in zero-shot classification. In the ScanObjectNN benchmark for standard fine-tuning, ULIP-2 reaches an overall accuracy of 91.5% with a compact model of only 1.4 million parameters. ULIP-2 sheds light on a new paradigm for scalable multimodal 3D representation learning without human annotations and shows significant improvements over existing baselines. The code and datasets are released at https://github.com/salesforce/ULIP.
Task¶
- 构建一个可扩展的多模态预训练框架用于 3D 理解 , 不需要人工标注就能进行大规模 3D 数据的预训练。
Technical Chellenge for Previous Methods¶
- 收集和采集 3D 数据
Previous Methods¶
Failure Case / Limitation¶
- 人工注释难以拓展
- 不够全面 might not provide sufficient details and lacks variations, or appears to be noisy
- 贵
Example
比如这张图,原始标注的语义信息就不太够,但是用 ULIP-2 标注的就比较全面。 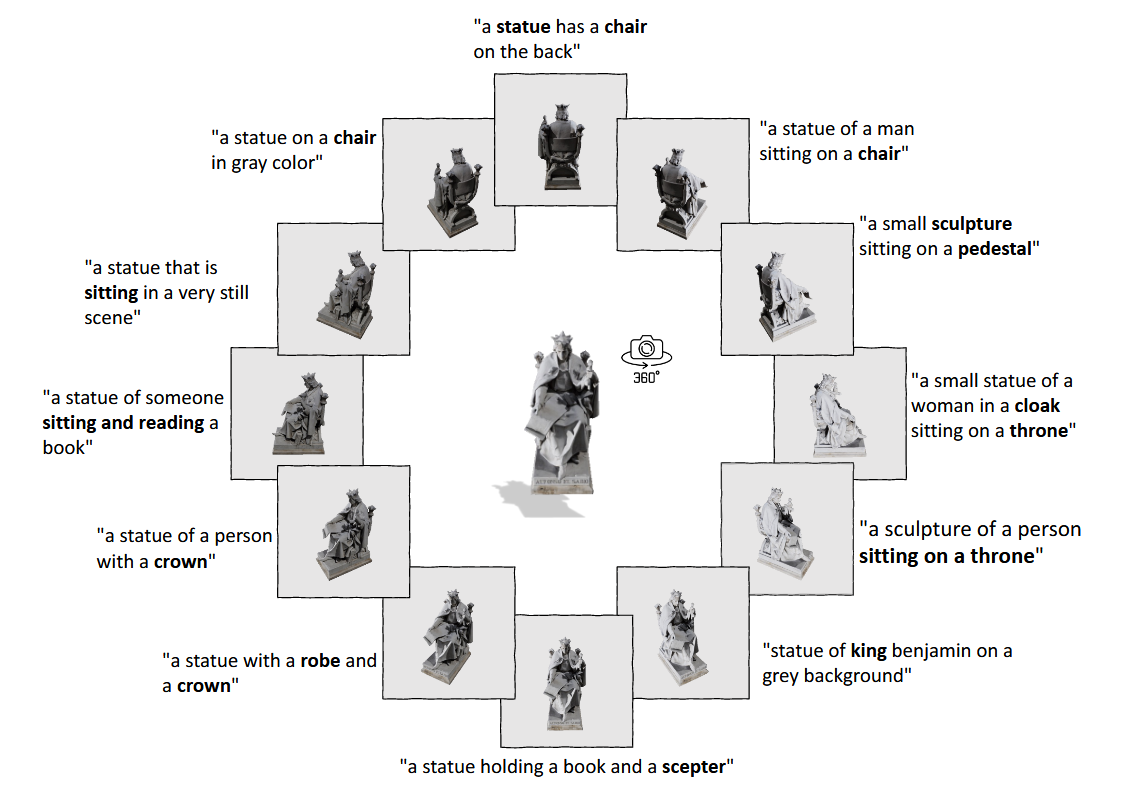
Our Pipeline¶
ULIP-2 采用大型多模态模型,从 3D 形状的整体角度为每个 2D 渲染的图像自动生成详细描述。ULIP-2 利用预先对齐和冻结的视觉语言特征空间来实现三元体模态之间的对齐:整体文本、图像和 3D 点云。预训练后,3D 编码器将用于下游任务。
Example
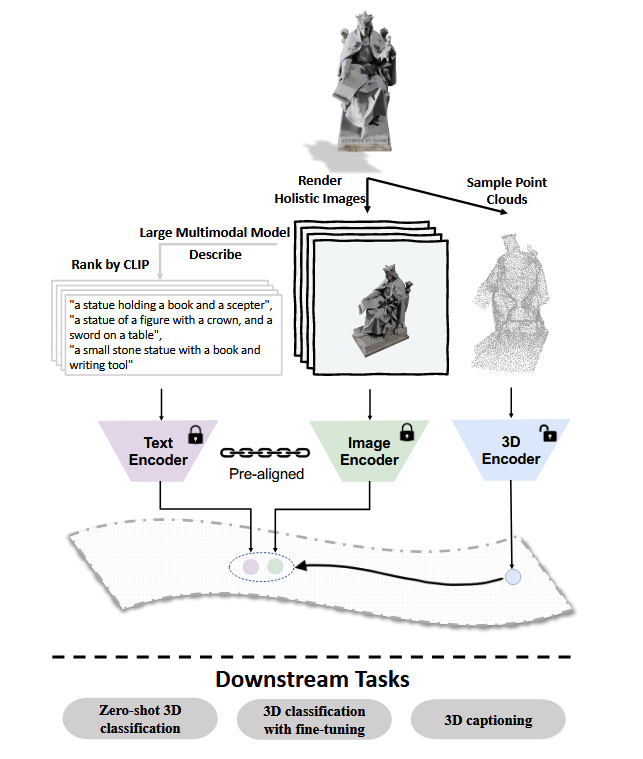
Key insight¶
- 3D 到 2D 就是用几个固定视角,然后用 multi-modality pre-training module 就可以生成每张照片的描述。就可以自动且可拓展地生成数据。
Technical contributions¶
- ULIP-2 有助于实现可扩展的多模态预训练,无需人工注释,使其适用于任何 3D 数据集,甚至是未标记的数据集。它完全依赖于 3D 数据,实现了更广泛的适用性和易用性。
- ULIP-2 在多模态表示学习方面取得了重大进步。在具有挑战性的开放世界 Objaverse-LVIS 基准测试中,ULIP-2 的准确率达到了 50.6% 的前 1%,比当前的 SOTA(OpenShape [22])高出 3.8%,尽管 ULIP-2 的框架更简单、更流线型 ; 对于 ModelNet40 上的零样本分类,ULIP-2 达到 84.7%,甚至优于一些完全监督的 3D 分类方法 [50]。此外,它在 ScanObjectNN 基准测试中确保了 91.5% 的总体准确率,只有 140 万个参数。此外,还展示了 ULIP-2 编码器的 LLMs,突出了它与不断增长的 LLM。此外,ULIP-2 可以与不断增长的 3D 数据容量和大型多模态模型的开发有效协同作用。
- 我们发布了两个大规模的三模态数据集
, “ULIP-Objaverse”和“ULIP-ShapeNet”三元组,由点云、图像和语言描述组成。表 2 中详细介绍了数据集的统计数据。
Method¶
- 用 ULIP 当 baseline 1. 输入 3D 模态 2. 提取点云 3. 生成图像 4. 用 BLIP-2 生成句子 5. 得到语言模态
- \(\displaystyle \tau\) 是温度系数, \(\displaystyle\mathrm{f}\) 是嵌入以后的特征
- 训练 3D 编码器,让这两个值加起来最小
Experiment¶
- dataset
- Objaverse
- ShapeNet
Example

- three downstream tasks
- the zero-shot 3D classification task involving multimodal inputs
- the standard 3D classification task involving a single modality
- the 3D captioning task involving 3D-to-language generation with LLMs
- Evaluation Metrics
- top-1 and top-5 accuracy for the zero-shot 3D classification task;
- overall accuracy and class average accuracy for the standard 3D classification task.
the zero-shot 3D classification task involving multimodal inputs¶
Example
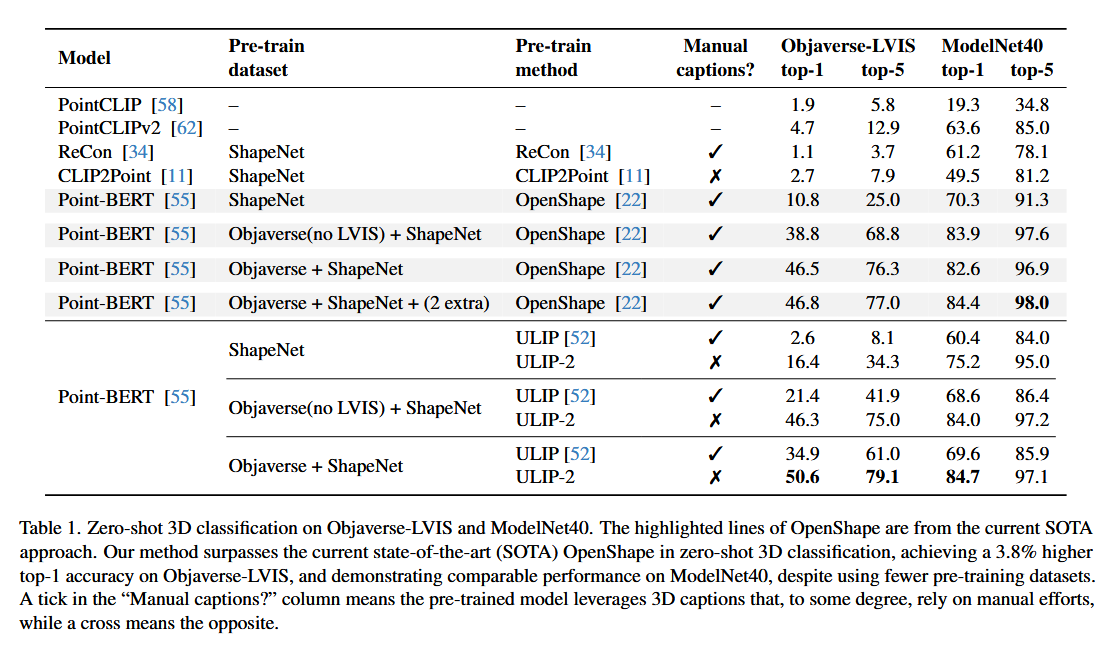
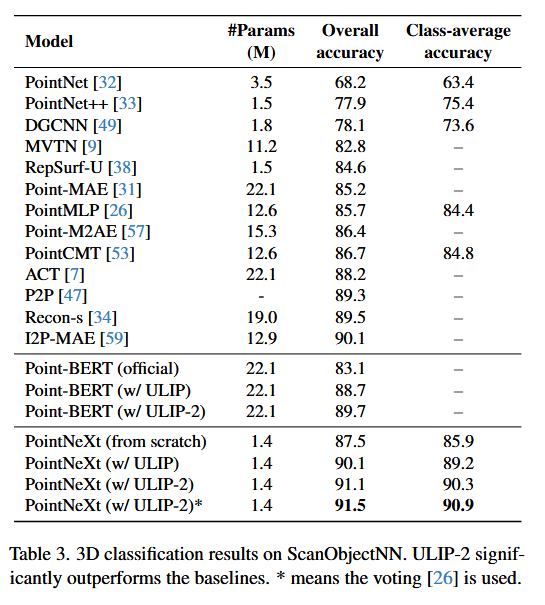
the standard 3D classification task involving a single modality¶
Example
the 3D captioning task involving 3D-to-language generation with LLMs¶
Example
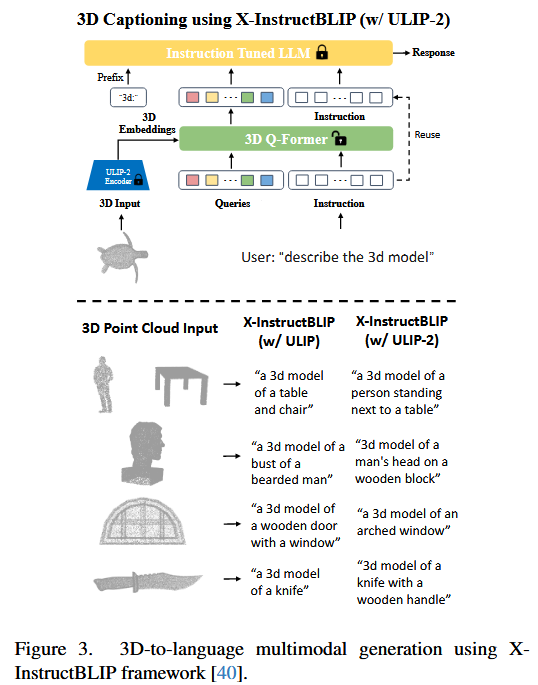
Example
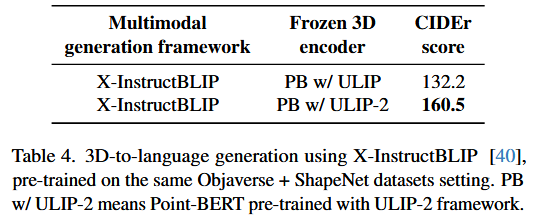
Ablation Study¶
- Ablation on the effect of the generated captions
- Different Large Multimodal Models
- Number of 2D Views Per 3D Object
- Top-k CLIP Ranked Captions Per 2D View
- Scaling Up the Backbone Models
Conclusion¶
Conclusion
We present ULIP-2, a novel framework for multimodal 3D representation learning. By leveraging large multimodal models for language description generation and scaling up the multimodal 3D pre-training, ULIP-2 not only addresses the quality and scalability challenges in existing multimodal 3D datasets but also demonstrates significant improvements in all downstream tasks. We also release "ULIP-Objaverse" triplets and "ULIP-ShapeNet" triplets, two large-scale trimodal datasets to foster further research. Limitations. ULIP-2’s pre-training primarily utilizes object-level 3D shape datasets, which inherently differ from scene-level 3D data in their distribution and complexity. Exploring the application of the ULIP-2 framework to scenelevel 3D data understanding, and leveraging the knowledge learned from object-level 3D data for this purpose, represents a compelling avenue for future research. Broader Impact. ULIP-2 aims to minimize human annotation in 3D multimodal pre-training, reducing labor but potentially impacting low-skilled job markets. This dual impact, a common concern in AI advancements, underscores the need for broader considerations in AI research.
- 创造了一种生成数据的方法,然后发布了 "ULIP-Objaverse" triplets and "ULIP-ShapeNet" triplets
Limitation¶
- 3D 数据集只有 object,数据集没有场景的
复现 ¶
相关论文 ¶
Generative Large Multimodal Models¶
- [[GPT]]
- [[GPT4]]
- [[BLIP-2]]
Multimodal Representation Learning¶
- [[CLIP]]
- SLIP
3D Point Cloud Understanding¶
- PointNet
- Point-BERT
- PointNeXt