约 645 个字 10 张图片 预计阅读时间 3 分钟 共被读过 次
Foundational Models for 3D Point Clouds A Survey and Outlook¶
FM: Foundational Models
- 提取其他模态的特征来弥补 3D 数据的理解
- 不进行大量数据采集 -> 弥合数据缺少的差距
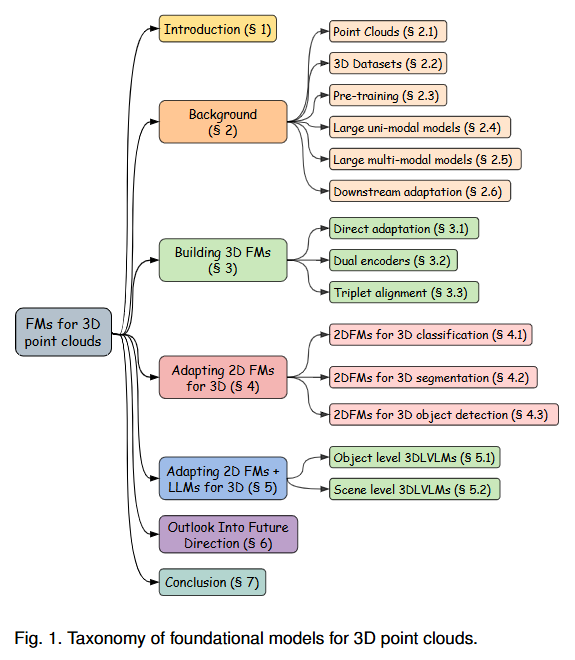 1. 用 2DFMs -> 3DFMs 2. 使用 2DFMs 来完成任务:点云分类 3. LLM + CV 来对齐
1. 用 2DFMs -> 3DFMs 2. 使用 2DFMs 来完成任务:点云分类 3. LLM + CV 来对齐
Contributions¶
- 全面背景说明
- 结构化分类
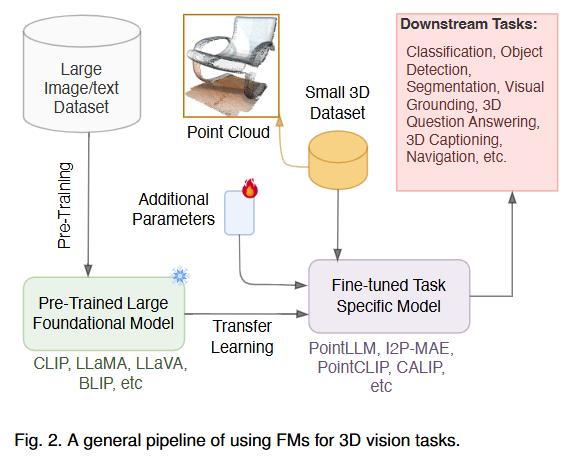
Background¶
- object-level
- 数据合成
- ShapeNet 51300
- ModelNet40 12311
- 3D-FUTURE
- 多视图
- DTU
- BlenderMVS
- 扫描的
- ScanObjectNN 15000
- GSO
- AKB-48
- CO3D
- colmap 生成 + 视频
- OmniObject3D
- 6000 个,啥都有
- 数据合成
- scene-level
- Matterport3D
- RealEstate10k
- ARKitScenes
- ScanNet
- ScanNet200
- ScanNet++
- 户外
- SemanticKITTI
- Paris-CARLA3D
- nuScenes
- extensions for 3D language understanging tasks
- Single Modality
- CV
- Vision Transformer
- MAE
- DINOv1/v2
- NLP
- BERT
- GPT1/2/3
- LLaMA
- CV
- Multi Modality
- CLIP
- BLIP
- Flamingo
- SAM
- Single Modality
- PEFT
- LoRA
- prompt-tuning
- QLorA
Building 3DFMs¶
 - ConvNet - PointContrast - OcCo - DepthContrast - Transformer - Point-BERT - Point-MAE - Voxel-MAE - SimIP - 他们没有用 2DFM -> 3DfM, 这里不讨论
- ConvNet - PointContrast - OcCo - DepthContrast - Transformer - Point-BERT - Point-MAE - Voxel-MAE - SimIP - 他们没有用 2DFM -> 3DfM, 这里不讨论
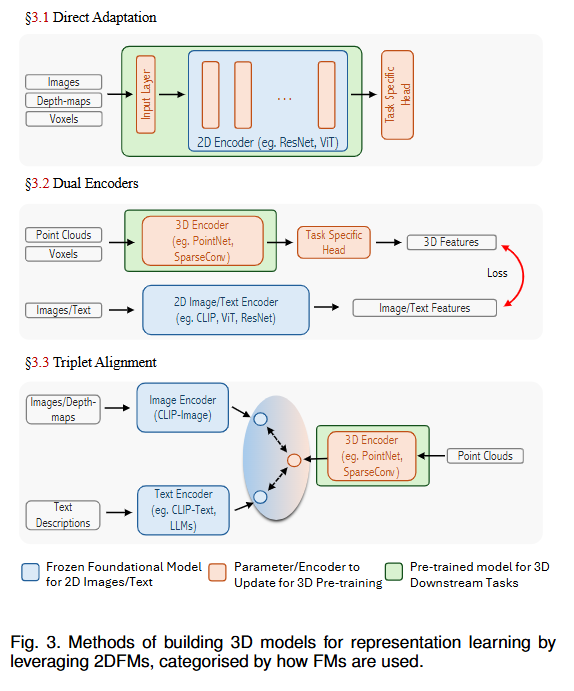
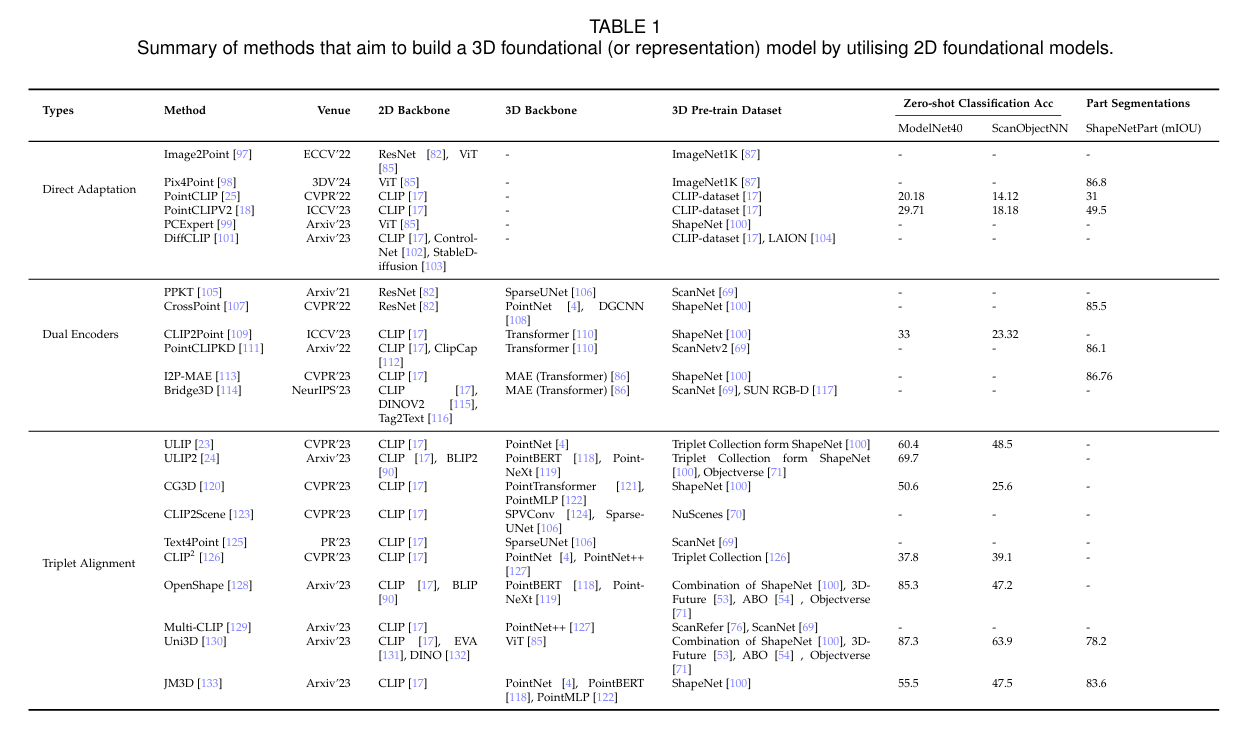 分三类:
分三类:
- 2DFM 作为 FM
- Image2Point
- 2D Kernel -> 3D Kernel
- Pix4Point -> 也就是把 3D point 进行 tokenization
- PCExpert -> 让 PC encoder 来学 Image encoder 的内容
- PointCLIP v1/v2 点云投影 -> CLIP
- DiffCLIP -> ControlNet 扩散模型 RGBD -> RGB
- Image2Point
- Dual Encoder
- PPKT -> 用上采样层解决缺乏像素级分辨率的问题 -> 用 2DFMs 训练 3DFMs
- CrossPoint -> 点云增强 + 对比学习,具体不是很了解
- CLIP2Point -> 3D PC -> RGBD <-> CLIP 视觉对齐 NT-Xent + InfoNCE
- PointCLIPKD -> 图像加上 ClipCap 点云用 PC Token + Concept query 然后蒸馏。不是很懂
- Bridge3D -> 2D FM + MAE -> 关注前景
- I2P-MAE
- Triplet Alignment
- ULIP
- ULIP-2 BLIP-2
- CG3D -> learnable prompt + extra parameters
- CLIP2Scene -> SCR SCTR
- Text4Point -> Text 2D 3D
- CLIP^2 -> text 2D 3D
- OpenShape -> larger dataset + 改进 text
- Multi-CLIP -> 3D 2D Text QA 上测评不错
- Uni3D -> 变大!
- JM3D -> 层次文本树
- JM3D-LLM
特定领域的模型 ¶
2DFMs 分类 3D ¶
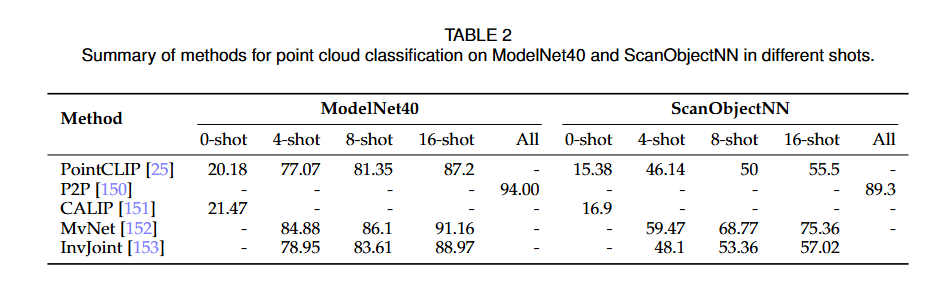 - CALIP - non-parametric - Bidirectional modifications - P2P - VPT 启发 - MvNet - 多视图投影 -> 注意力机制 -> 视图融合 - InvJoint - 混淆矩阵 -> 解决投影可能的问题
- CALIP - non-parametric - Bidirectional modifications - P2P - VPT 启发 - MvNet - 多视图投影 -> 注意力机制 -> 视图融合 - InvJoint - 混淆矩阵 -> 解决投影可能的问题
2DFMs 分割 3D ¶
3D part Segmentation¶

- PointCLIP V2
- PartSLIP (GLIP + free-form text + 3D voting and grouping -> 2D bounding box -> 3D bounding box)
- ZeroPS
- 改进投票机制
- 提出合并 part 算法
- 找到 2D box 和 3D box 的最佳匹配
- PartDistill
- 蒸馏
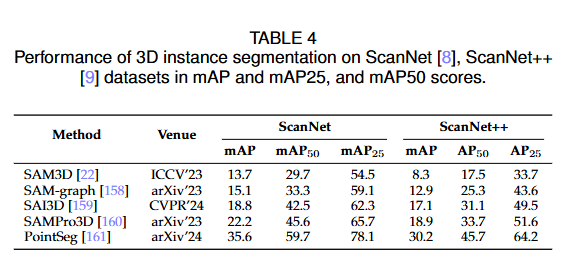
- SAM3D
- multi view -> SAM -> 搞回去
- SAM-Graph
- 感觉挺有意思的,有空去看看
- SAI3D
- SAMPro3D
- PointSeg
Open-Vocabulary Segmentation¶
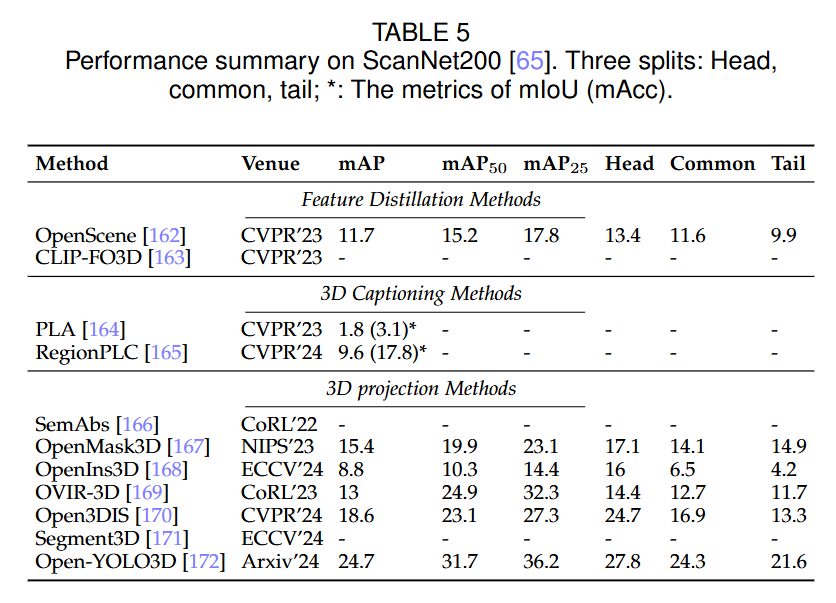
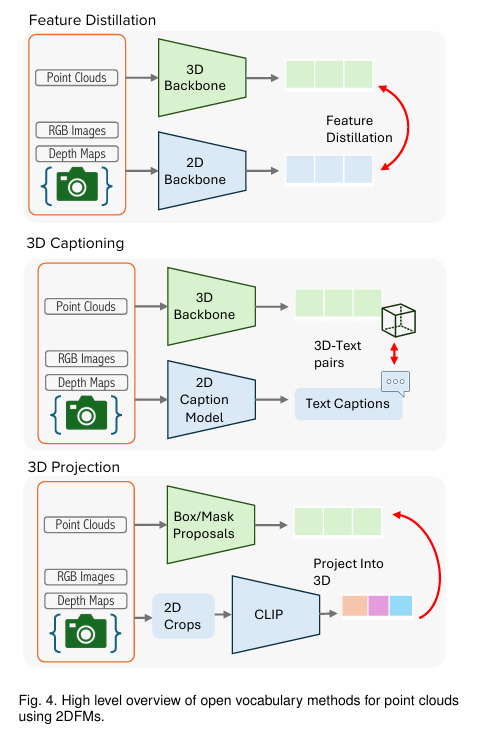
2DFMs for 3D obj detection¶
- SAM3D
- VFMM3D
- FM-OV3D
2DFMs + LLMs for 3D Tasks¶
Object Level¶
- Cap3D
- 3D assets -> 2D image -> BLIP2 generate -> CLIP filter -> GPT4
- XinstructBLIP
- Qformers
- Linear Projection
- 指令集稀缺 -> based on retrieval data enhancement
- GPT4Point
- ShapeLLM
- 多级形状理解
- Recon -> Recon++
- MiniGPT-3D
- MoE + LoRA + norm tuning
- GreenPLM
- LLaNA
- NeRF + LLM
Scene Level¶
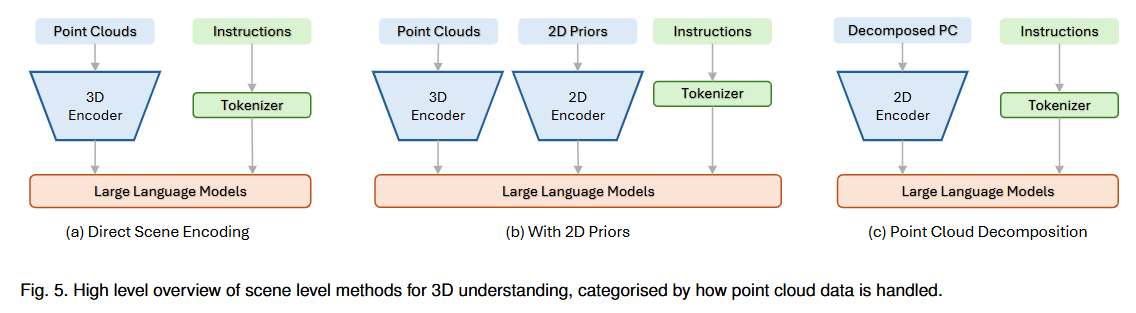
直接场景编码 ¶
- LL3DA
- SIG3D
基于 2 维先验 ¶
- RegionBLIP
- 3D-LLMs
- LEO
- 看起来挺有意思的
- SpatialRGPT
- 2D image -> 3D scene graph
- 重点关注开放词汇检测和分割、度量深度估计和相机标定以生成准确的空间表示
点云分解 ¶
- Uni3D-LLM
- LLaVA-3D